Measuring the city: metrics and indicators
📥 Click here to download this document and any associated data and images
This section will cover:
- common metrics and indicators used in urban analysis,
- spatial units and measures of aggregation often used for urban analysis, and
- limitations and biases for working with urban datasets to keep in mind when working with urban data.
Common metrics and indicators for urban analyses
The table below lists examples of variables/metrics that are used in urban analyses, grouped by topic.
| Topic | Common metrics |
|---|---|
| People / socioeconomics | - Population density (e.g., population per square kilometer) - Population change over time - Average household size - Median household income - % population from a given racial-ethnic category (e.g., % Asian) - % population from a given educational level (e.g., % with a high school degree) - # of crimes by census tract - % votes for a given party by riding (e.g. in Toronto) - Displacement risk - Social vulnerability index - Inequality metrics (e.g., Gini index - US & Canada) |
| Housing | - % owners vs. renters - % single family homes vs. multifamily homes - Median rent - Median home sale price per sq. ft. - Vacancy rate - Housing cost burden (share of income spent on housing costs) - Core housing need (housing suitability plus cost burden) - # of units built or permits issued over time or in a given neighborhood (e.g., Canadian ADU analysis; market-rate housing in the Bay Area) - # of dedicated affordable housing units |
| Land use | - % change in land cover or forest area (Toronto example) - % of land zoned single-family vs. multifamily (e.g., zoning policy changes; residential zoning in Canadian cities, National Zoning Atlas) - Walk score - Entropy index for land use |
| Economics / employment | - Job density overall or for a given industry sector - Location quotient (definition) - % of jobs from a given occupation - % of jobs from a given industry sector - % of workers commuting in/out of a given boundary (commuting patterns) - Venture capital investment by city - Sales and transaction data - Downtown recovery post-pandemic (e.g., trends; Urban Activity Atlas) |
| Transportation | - % of people who commute via public transit vs. car (commute mode) - % population within 1-km of a rail station or population near a given transit station (public transit accessibility) - E-bike trip distance - % or number of bike share trips by neighborhood or dock station (e.g. Bike share trips in Toronto) - Density of traffic violations by street or by intersection (e.g. Traffic violations) - # of public electric vehicle charging stations by neighborhood (US/Canada Alternative Fueling Station Data) - Pedestrian counts |
| Environment | - Prevalence of PM 2.5 by census tract (e.g. Emissions/air pollution) - Average temperature by census tract (e.g., heat exposure in Toronto) - % population within 0.5-km from a public park (park accessibility) - % of land at risk of flooding in a given city or neighborhood (e.g., Toronto; FEMA; Canada) - % tree canopy coverage by census tract (e.g. Toronto, U.S. data) - # of census tracts that are Environmental Justice communities |
| Health | - Average life expectancy - Prevalence of chronic diseases by census tract (e.g., diabetes, asthma) - # of gun deaths over time |
Common spatial units and measures of aggregation
Urban data is often linked to specific places. This is often called spatial or geographic data.
When analyzing spatial data, our analysis is often at the level of specific spatial units or unit of aggregations. Sometimes our data is directly collected at these units, while sometimes it is useful to aggregate large datasets to these units to help analyses and visualizations.
When working with urban data, it’s essential to consider how geographic boundaries are defined. Standard units like census tracts or zip codes may not reflect actual community identities and are subject to change over time.
Below are spatial units and types of encoding that are often used for collecting and analyzing urban data.
In our notebook on Spatial data and GIS, we go into details on how different spatial data is structured, and how we can begin to view, explore, and analyze different data in GIS.
Administrative or political boundaries
Political boundaries that delineate jurisdictions for different levels of government, from national down to local levels. Countries, provinces or states, counties, municipalities, electoral districts or city wards, and within cities, neighbourhood planning areas, are all examples of commonly used spatial units.
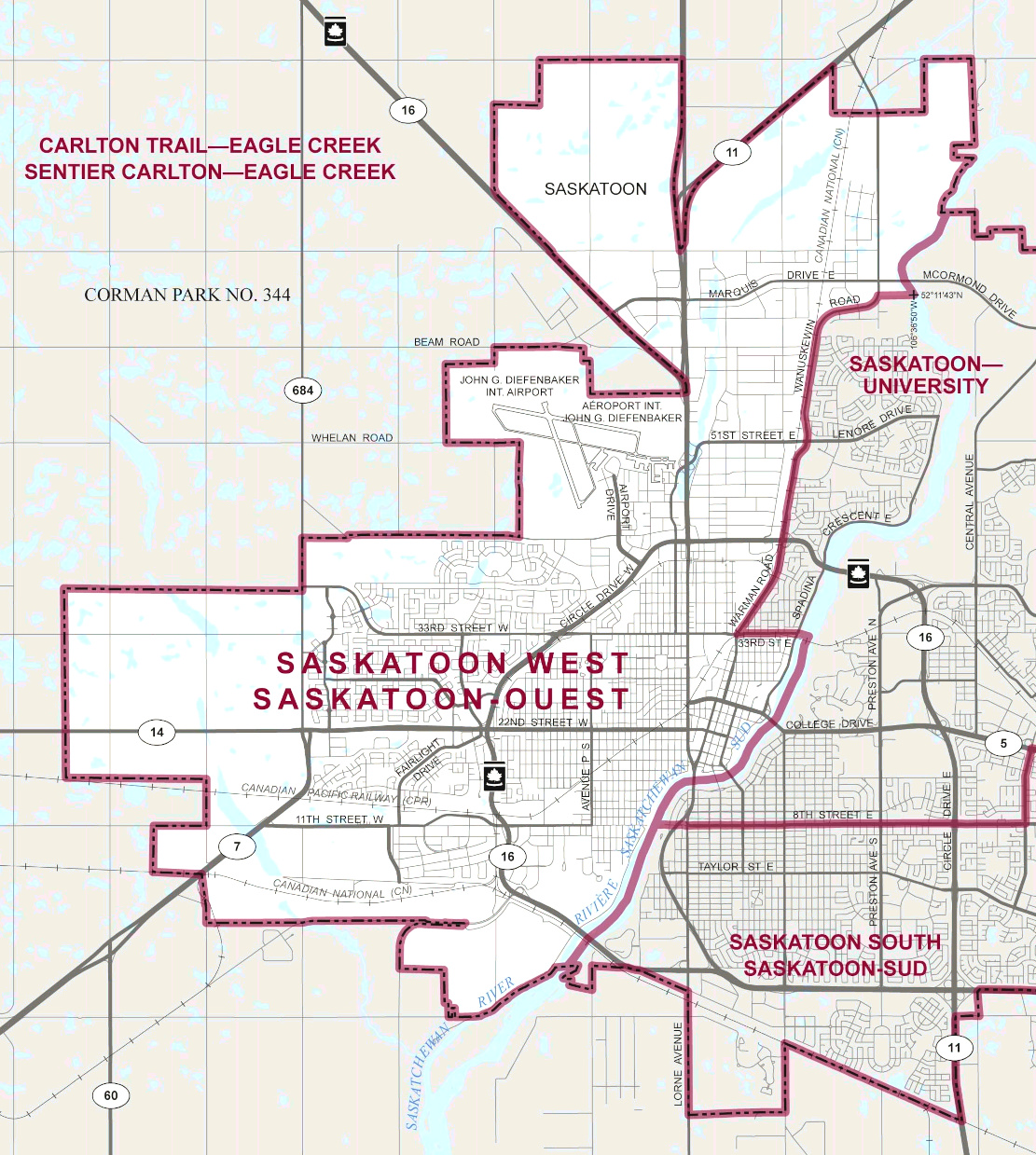
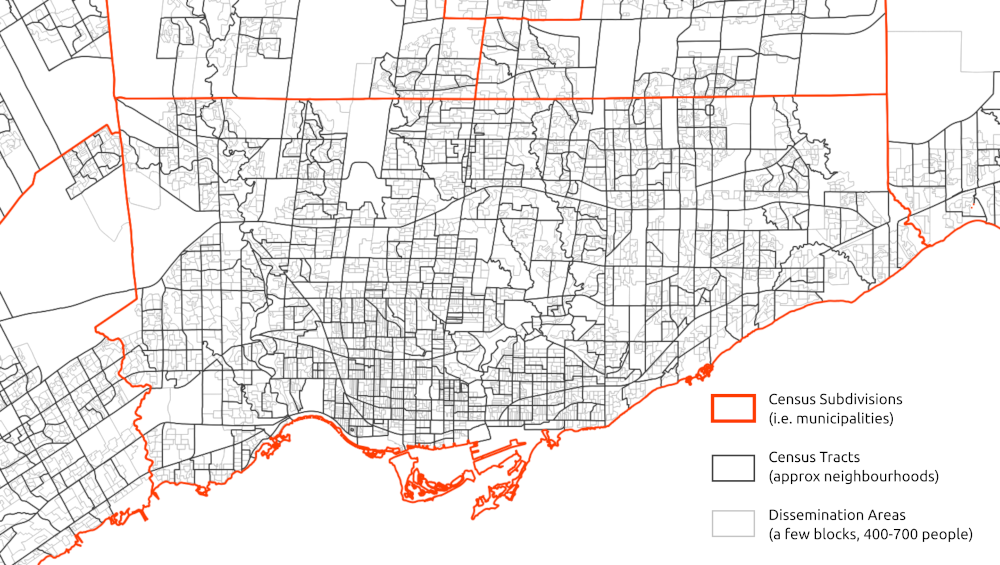
Census geographies
National censuses aggregate data to a variety of spatial units ranging in size, many are the same as administrative and political boundaries, as well as many smaller-geography boundaries that are super useful for urban- and neighbourhood-scale maps and analyses. Census tracts (usually in the range of 2,500 and 8,000 persons) and Dissemination Areas (400 to 700 persons) are two scales that are often used in Canada.
For more information about geographic boundaries of Canadian census data, check out Statistics Canada’s documentation or see our chapter on Canadian census data. For more information about U.S. census boundaries, see the U.S. Census documentation or our chapter on U.S. census data.
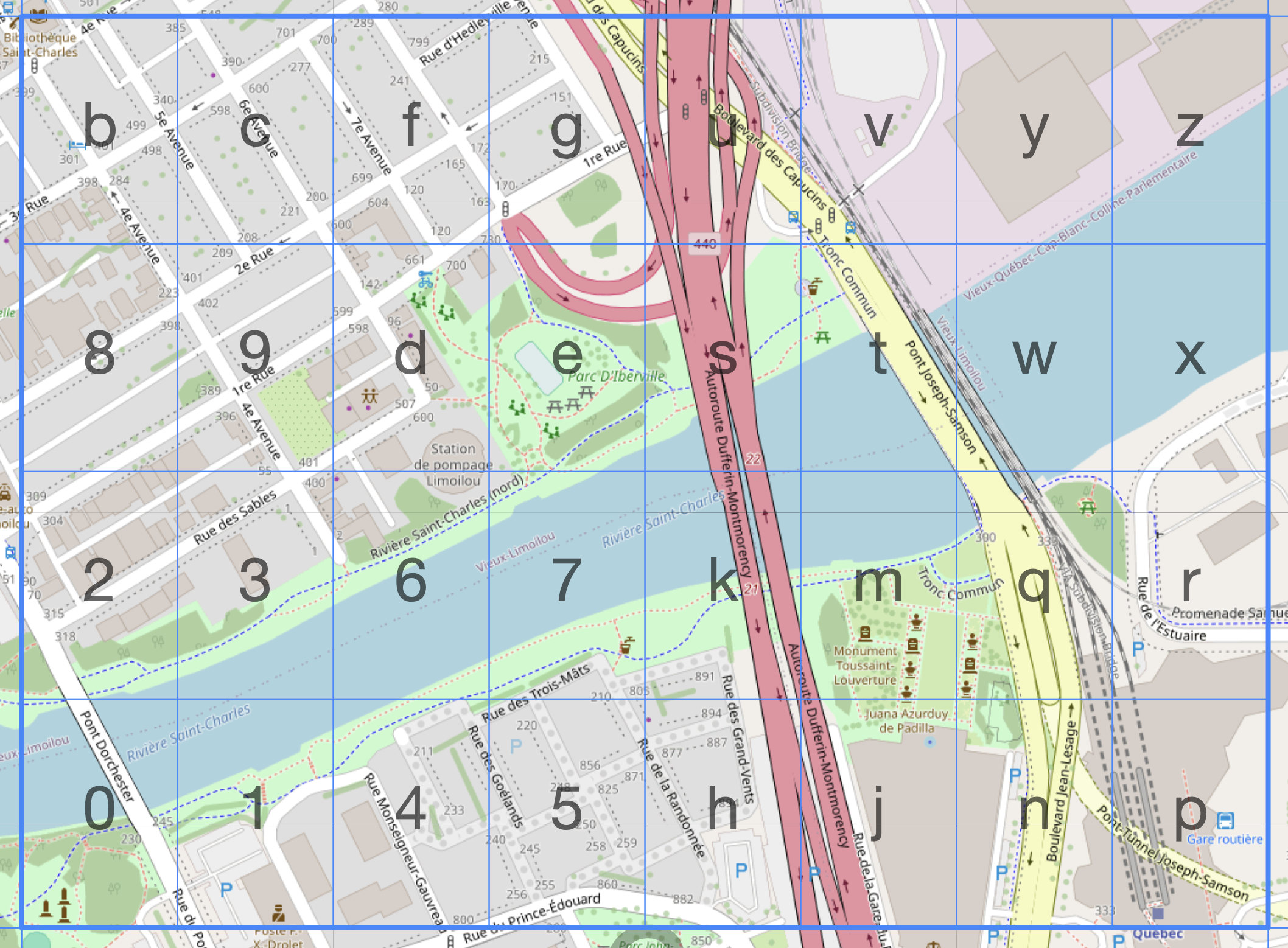
Grids
A grid is repetitive tesselation spread across the surface of a map. Grids are used in spatial analysis when existing boundaries are unavailable, unsuitable, or when evenly sized, uniform areas are required. Geohashes, which uniquely identify specific regions according to their latitude and longitude everywhere on Earth, are one type of commonly used grid.
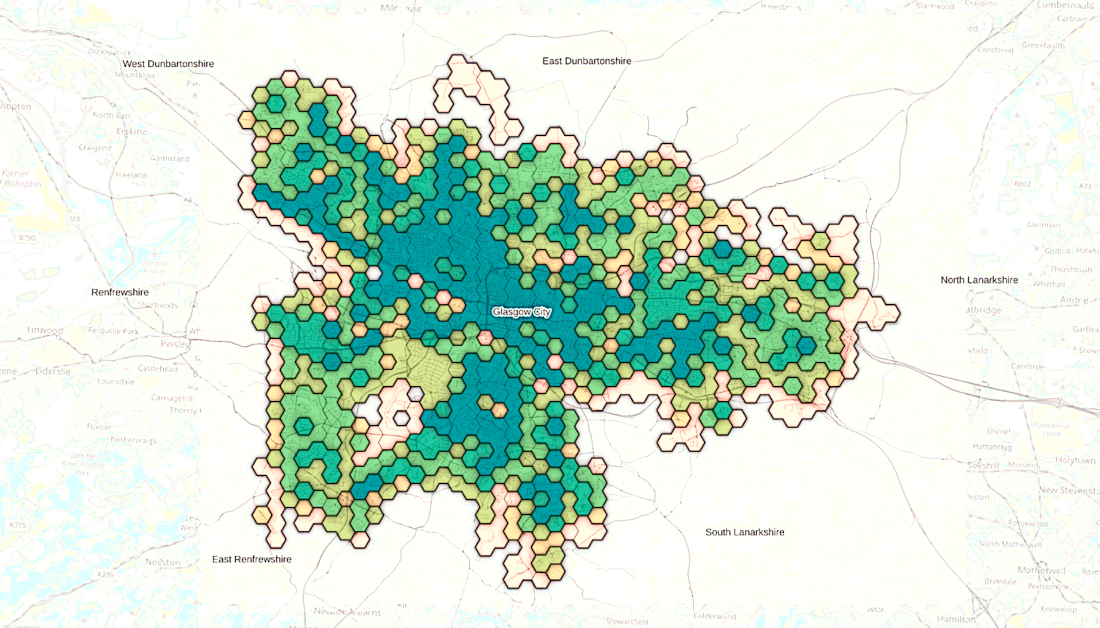
Grids do not have to be 4-sided. Triangular and hexagonal grids are often used for some studies. Hexagon’s are often recommended since they are the regular polygon with the most sides (i.e. can closest represent a circle), that can tesselate without any gaps.
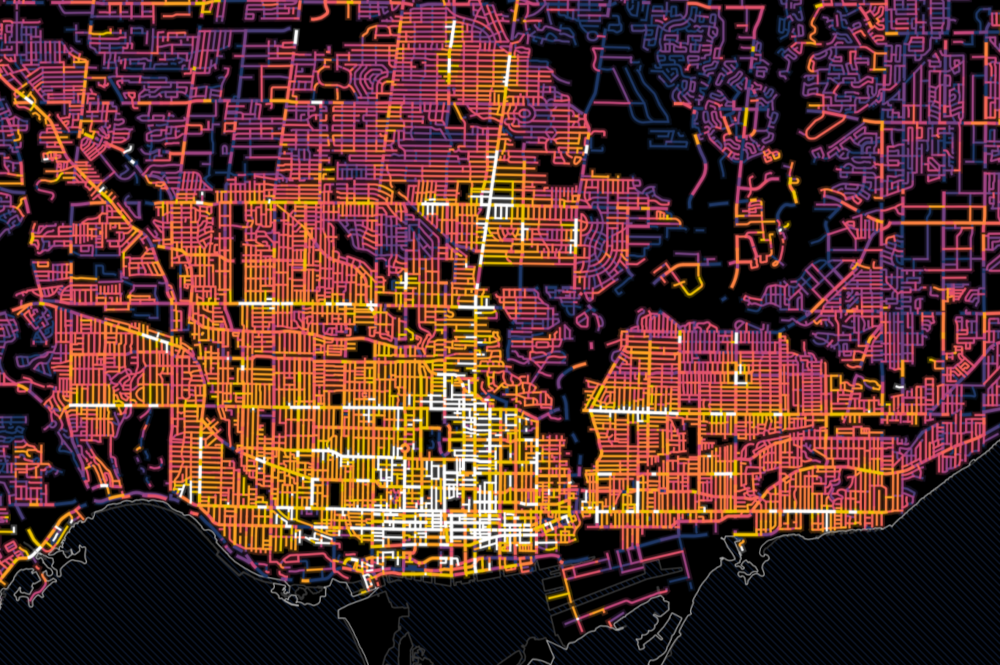
Streets
While streets are often added to maps to provide geographic context, streets can also be their own unit of analysis. For example, traffic flow could be measured on street segments throughout a city. In the image below, streets are coloured by how many parking tickets that they have.
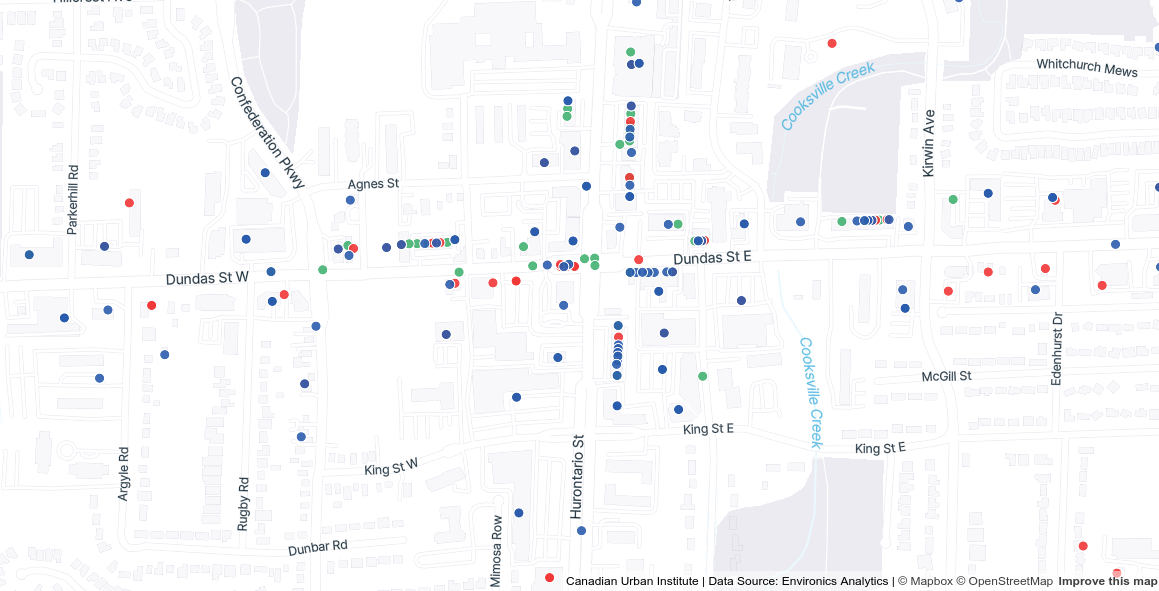
Addresses
Some urban data is measured or collected at the address level (e.g., the locations of businesses, non-profits, or community facilities). To map this kind of data or compare address locations with other spatial data, addresses are often geocoded, or converted into geographic coordinates (latitude and longitude). See our Spatial data and GIS tutorial for more on geocoding.
Biases and limitations of spatial data
When collecting and analyzing data, it is important to verify the quality of the dataset. Some data is incomplete or has missing values, which can bias the results, especially if data from certain categories is missing disproportionately. For example, if income data is missing more often for lower-income individuals, the results may overestimate average income and under-represent vulnerable populations.
These are a few important sources of bias or limitations when working with spatial data that are important to be aware of when working with data linked to places.
Self-reporting bias, when individuals report inaccurate information about themselves in a survey. This can be intentional (e.g., under-reporting income or over-reporting education) or unintentional (e.g., forgetting details). This can lead to biases in the final dataset and any subsequent analysis.
Ecological fallacy is the phenomenon of drawing conclusions about individuals based on the group they belong to. For example, one might infer that everyone in a census tract with an overall high median income is wealthy. Although the median income is high, there may be low income residents who live in the tract whose incomes are not close to the median.
Edge effects in spatial analysis refer to the limitations or distortions that occur at the boundaries of a study area. They can bias results or reduce accuracy, especially when spatial patterns or processes extend beyond the area being analyzed. For example, let’s say you were mapping access to healthy food in a city. Your map may show that one corner of your city does not have a grocery store, leading to a conclusion of it being a food dessert. But if you didn’t consider grocery stores just outside the edge or boundary of your city adjacent to this corner, this may not be the case.
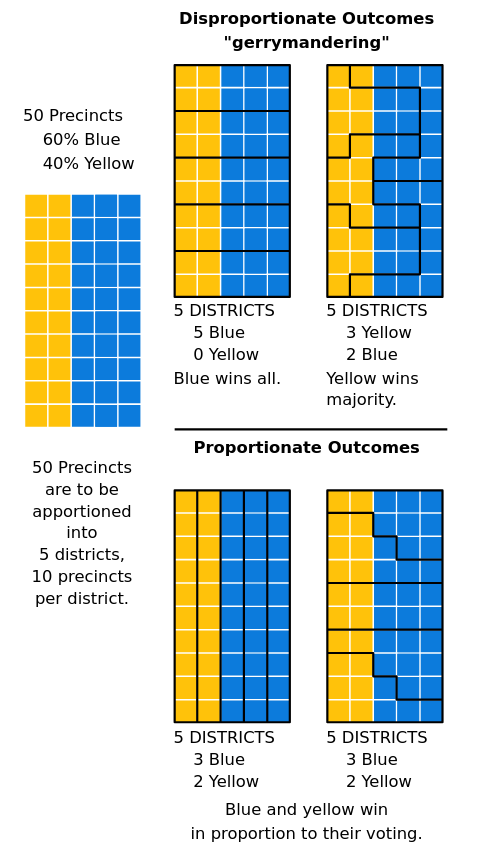
Modifiable areal unit problem (MAUP) is another source of bias when working with spatial data. It is a form of statistical bias that results from the fact that changing the scale or shape of aggregation units leads to different results. Gerrymandering is a classic example of intentional MAUP to obtain specific voting outcomes. Check out the graphic below, we can see the results of how different spatial units are arranged would impact the overall results of an election. Overall, it is important to think critically when working with different spatial units to avoid misrepresenting data or cherry-picking results.