Maps and visualizing spatial data
📥 Click here to download this document and any associated data and images
This section will cover:
- different types of maps
- how to decide what to show (or not show) on a map
- how to style a map
- including multiple layers on a single map
- what to include in finalized map layouts
Overview
Maps and spatial data visualizations can either be created at the research stage when we are trying to uncover patterns in the data, or as polished communication visuals, when we want to convey patterns in the data to our intended audience.
Cartography is often defined as the science and art of creating maps. It often involves decisions about …
- selection of data to include on the map
- generalization of data to reduce complexity and clutter
- how we want to style and symbolize our data
- how to order and layer data
- what other map layout elements to include (e.g. title, legend, north arrow), as well as how to design these to make a map easy to understand
This page will cover the basics of what goes into making maps and spatial data visualizations, following each of the steps above.
The last part of this notebook shows an example in QGIS of how to create maps with data-defined styling, for both categorical and numeric data.
If you are interested in creating specific types of maps, check out the following notebooks:
Types of maps
Reference & thematic
Almost all maps can be thought of as either:
- Reference maps, which provide base geographic information (e.g. streets, land forms, water, etc.) often for locating places or for navigation. Google Maps is probably the most well-used example.
- Thematic maps, also called geographic or spatial data visualizations, emphasize patterns or trends tied to a specific theme (e.g., population density, election results, air pollution, etc.).
Reference maps are often used as base layers for thematic maps.
For example, if we’ve collected a dataset about the location of public washrooms in a city, the first thing we might want to do is simply see where they are located by overlaying them onto a base map in GIS. This would be an example of a simple thematic map.
Here are a few examples of thematic maps that we’ve created, each with different urban data, objectives, and audience in mind.
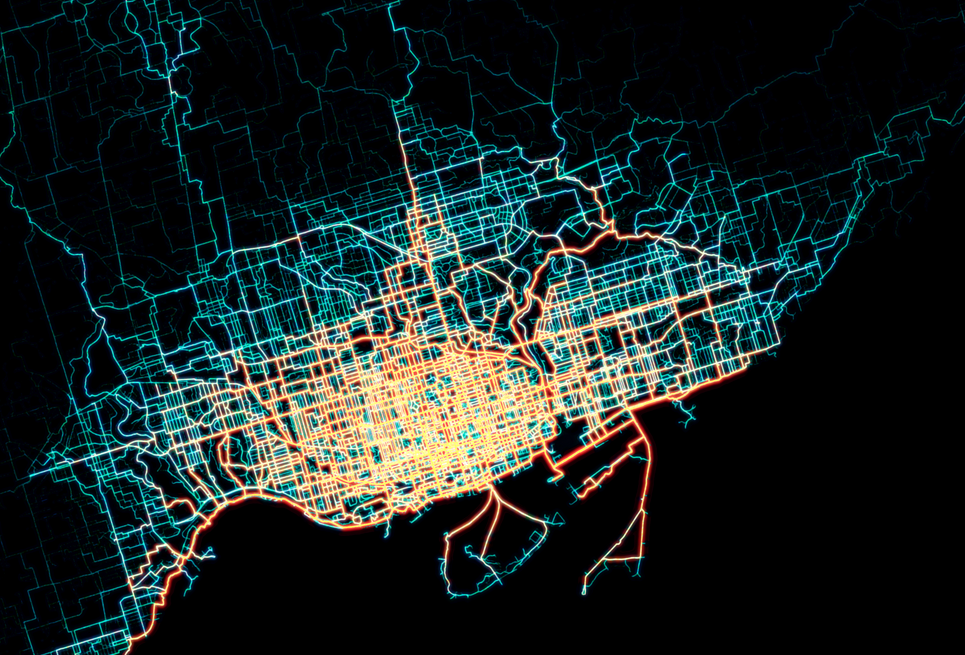
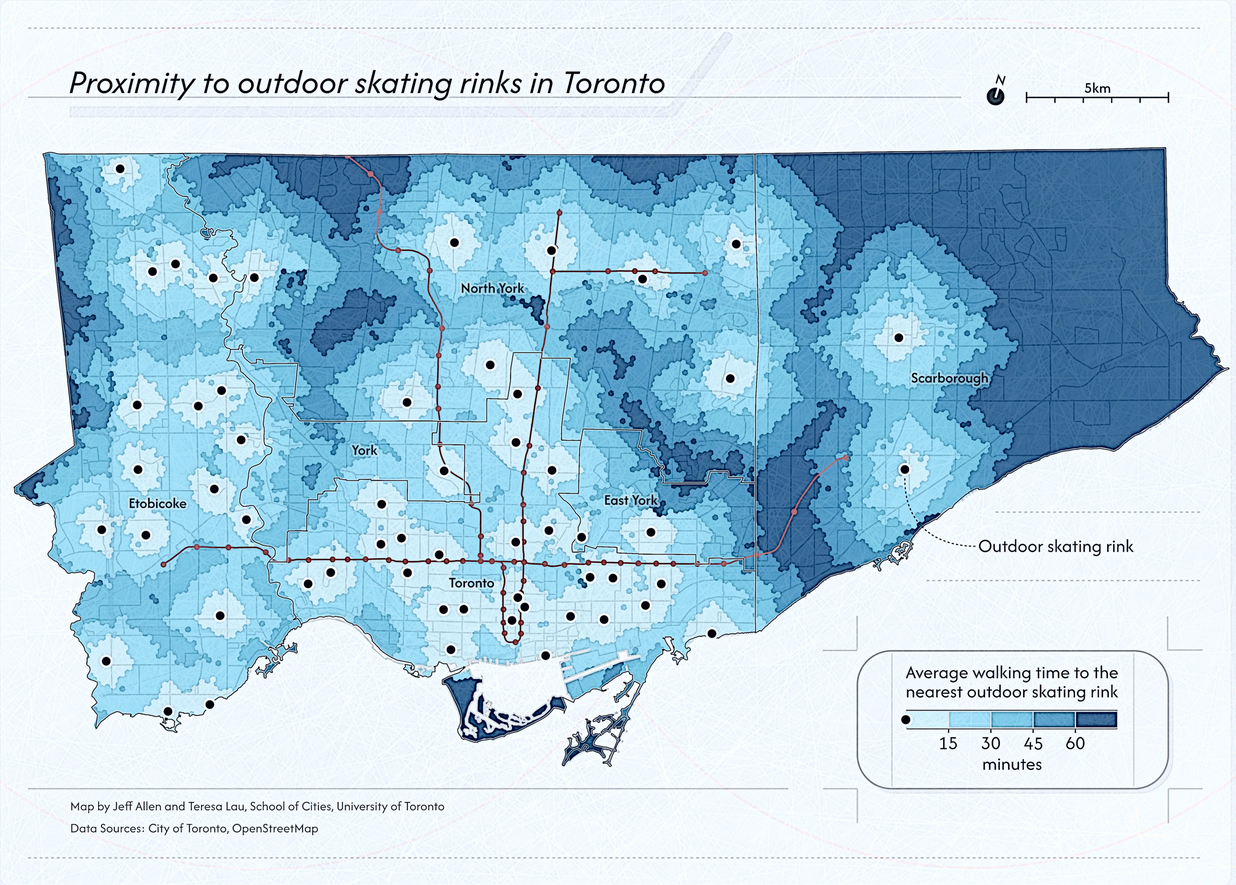
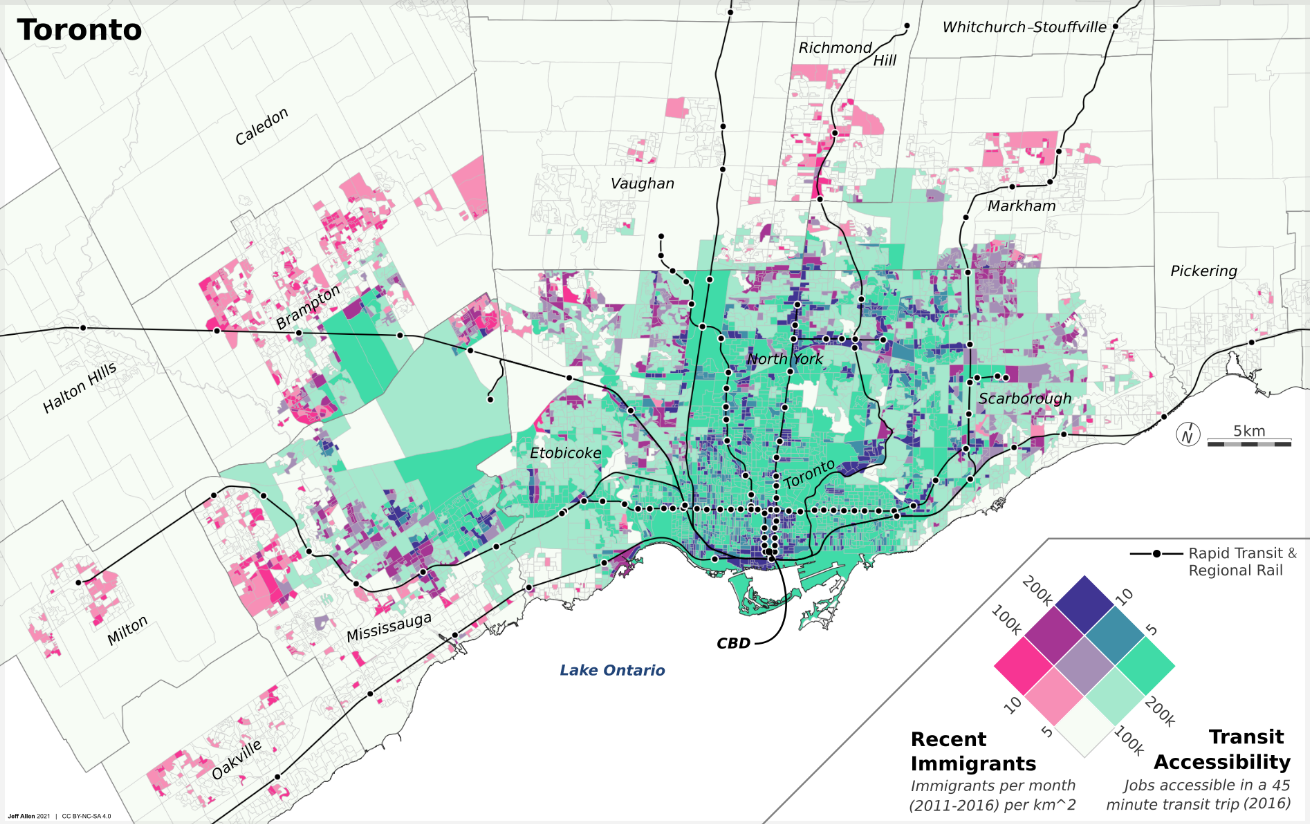
Static & interactive
Static maps are fixed, pre-generated images that display geographic information in a single, unchangeable format. They are ideal for simple visualization, printing, or when interactivity isn’t needed—such as in posters, reports, or static web images.
Static maps can vary in size from just a few dozen pixels on a screen or a small figure in a report, to graphics in a slide deck, to large maps printed as posters or dozens of maps as part of a series, like in an atlas. The three maps shown above are examples of static maps.
Interactive maps are digital and allow users to engage with the content by zooming, panning, clicking for details, or filtering data. They are best for exploration, real-time applications, user-driven analysis, or providing increased engagement via animation in a data-story. Here are a few examples that we’ve developed at the School of Cities:
- Urban Activity Atlas
- Heat Vulnerability in Toronto
- Knowledge of Languages in the Greater Toronto & Hamilton Area
Interactive maps can provide flexibility and deeper engagement with spatial data. However, interactive maps typically are much more work to create than a static map as they include all the visual design thinking in a static map, plus additional thinking about how users interact with them and how the maps respond to user inputs, as well as increased technical development time.
Our general recommendation is to always start with creating static maps, and then move on to creating an interactive version only if a static version is insufficient at conveying the story in your data that you want to convey.
If designed well, static maps can be super effective at highlighting key trends and stories in spatial data in a quick and easy to read way.
What’s on the map?
How do we decide what we are going to include on our map? Sometimes this may be obvious in terms of the key datasets that we want to visualizes, but particularly with any reference layers, this can often require a lot of minor subtle choices.
This is because maps are always abstractions of reality. It is impossible to show everything in the world on a piece of paper or a screen - nor would we want to, as we usually want to focus our reader’s attention on specific data point(s), trend(s), or story.
Creating maps and spatial data visualizations therefore often involves making decisions about how to select and generalize spatial data to reduce visual clutter and focus on specific data points.
Cartographic selection
Cartographic selection is about picking the most important things to draw on a map so it’s not too crowded. Imagine drawing a treasure map — you’d likely want to show big landmarks like mountains or forests, but leave out tiny rocks or every individual tree.
In practice, this can include deciding whether or not to include a dataset at all when creating a map.If we do decide to include the dataset, we may want to filter it to only show certain features.
For example, you may want to include a dataset of public transit lines as a reference layer for a map of your city. However, you may not want to include every single transit route. An example of cartographic selection would be to pre-filter the data by mode so we only show major transit lines (e.g. only show metro/subway) or frequency (e.g. only show routes where a bus or train comes every 10 minutes or less). Now of course if the goal of your map and research is about public transit at large, you may want to include all the routes.
The process of selecting some, but not all of the data that you have available, reduces clutter on your maps and can make them easier to read.
What data to include depends on your objectives, audience, and story.
Cartographic generalization
Similar to selection is cartographic generalization, which is when mapmakers simplify real-world details to make maps clearer and less cluttered, especially at smaller scales.
For example, a coastline with tons of tiny twists and inlets might get smoothed out to keep the overall shape but remove unnecessary complexity. This helps the map stay readable without losing its key features. It’s like sketching a quick but accurate version of a photo instead of drawing every single pixel.
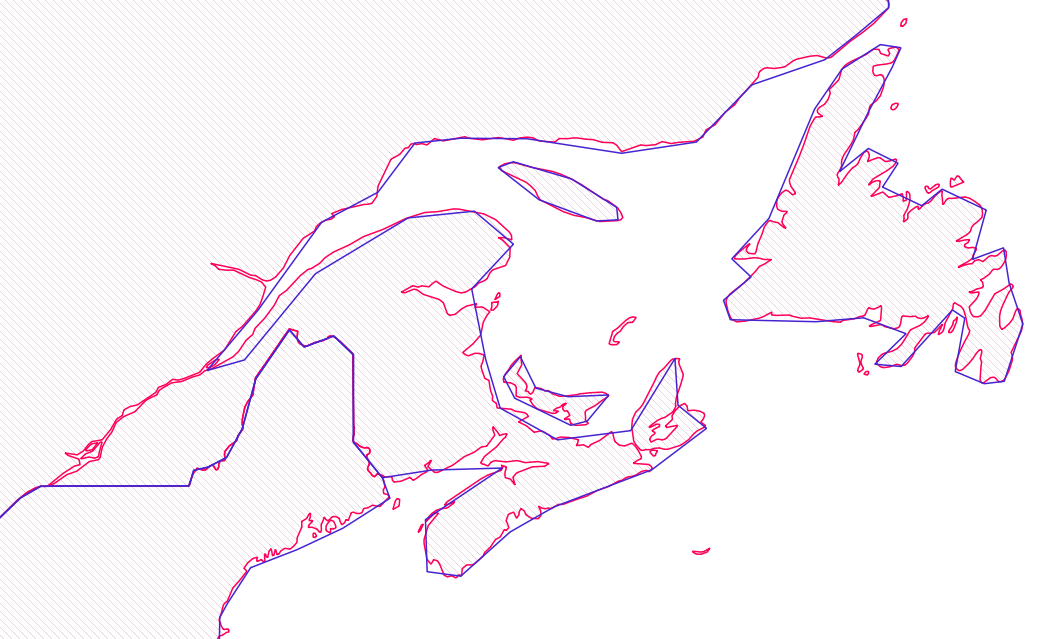
Another example would be a dataset that lists sports and recreation facilities in a city by primary use (i.e. baseball, football, tennis, etc). We could choose to have a different colour or symbol for each of these use types (i.e. green for tennis and blue for baseball), or generalize so they all look the same (e.g. the same shade of green).
Symbols and layer styling
Once we’ve decided what we want to include on our map, we have to decide how we want to style each layer. In some mapping tools, like QGIS, style options are often called Symbology.
Below are the most commonly used graphic styling options available for vector data layers. If you’ve worked with other design software, especially vector graphic software, many of these will be familiar.
Points:
- Symbol type (e.g. circle, square, etc.)
- Size
- Fill colour
- Stroke colour
- Stroke width
- Opacity
Lines:
- Width
- Colour
- Stroke style (e.g. solid, dashed, etc.)
- Opacity
Polygons:
- Fill colour
- Fill pattern (solid, hatching, etc.)
- Stroke colour
- Stroke width
- Stroke style (e.g. solid, dashed, etc.)
- Opacity
Note that there are often additional styling options beyond those listed above.
Single-rule styling
Single-rule styling is when we want all features in a dataset to look the same, regardless of how they may different in terms of their attributes
In the example in our notebook on introducing spatial data and GIS, we created a simple map of Toronto where we had two vector datasets 1) ward administrative boundaries (polygons) and 2) public libraries (points).
Each of these layers is styled via a single rule. For example, all public libraries are shown as blue squares, even though some libraries may be larger than others or have longer opening hours.
Data-defined styling
A powerful feature of tools such as QGIS or Python to make maps is that we can visualize spatial data based on a set of rules relating to their associated attribute data. For example, we could:
- Colour census tract data based on median income
- Size business point data based on their number of employees
- Shade different land-cover (wetlands, forest, farmland) with different textures for each category
- Style street network data based on quality and safety of cycling infrastructure
- Many more!
Many of these options use visual variables like size, hue, saturation, orientation, etc. as shown in our data visualization notebook.
Let’s look at a couple examples in QGIS! (If you haven’t worked with QGIS before, check out our intro to spatial data and GIS notebook)
Styling categorical data
For the first example, let’s try to create a map of public washrooms in Toronto in QGIS, using some categorical based styling - where different categories or groups are styled with different colours or symbols.
- Washroom facilities (a point dataset of public washroom facilities in Toronto)
- Centrelines (a line dataset representing a mix of features like streets, railways, power lines, rivers, etc. in Toronto)
- Green space (a polygon dataset of green spaces and public parks in Toronto)
- Lake Ontario (a polygon of Lake Ontario)
📥 Click here to download this data
(All of this data is from the City of Toronto, except for the Lake Ontario polygon, which is from OpenStreetMap)
Load the data into QGIS and re-order the layers such that the washroom locations are at the top. For our map, the washrooms are the key data we want to show (i.e. the foreground), while the others are visual reference (i.e. the background).
After loading in the data, right click on each of the layers and then click Open Attribute Table to view the what data is linked to each feature.
While most columns of a spatial dataset could be styled categorically, many wouldn’t be interesting to represent. Alternatively if there are many different categories, showing too many could lead to excessive visual clutter.
So let’s pick something simple to start with. We’ll colour the washrooms by their type, which only has two options "Washroom Building" or "Portable Toilet"
To style a layer based on a category, right-click the layer, go to Properties, then Symbology, and then at the top there will be a dropdown where one of the options is Categorical. The below dropdown is the Value, which is the column in your data that you want to use to define the style of your data. For this example, lets pick type. Then click Classify. You should see each possible category display with a default symbol next to it.
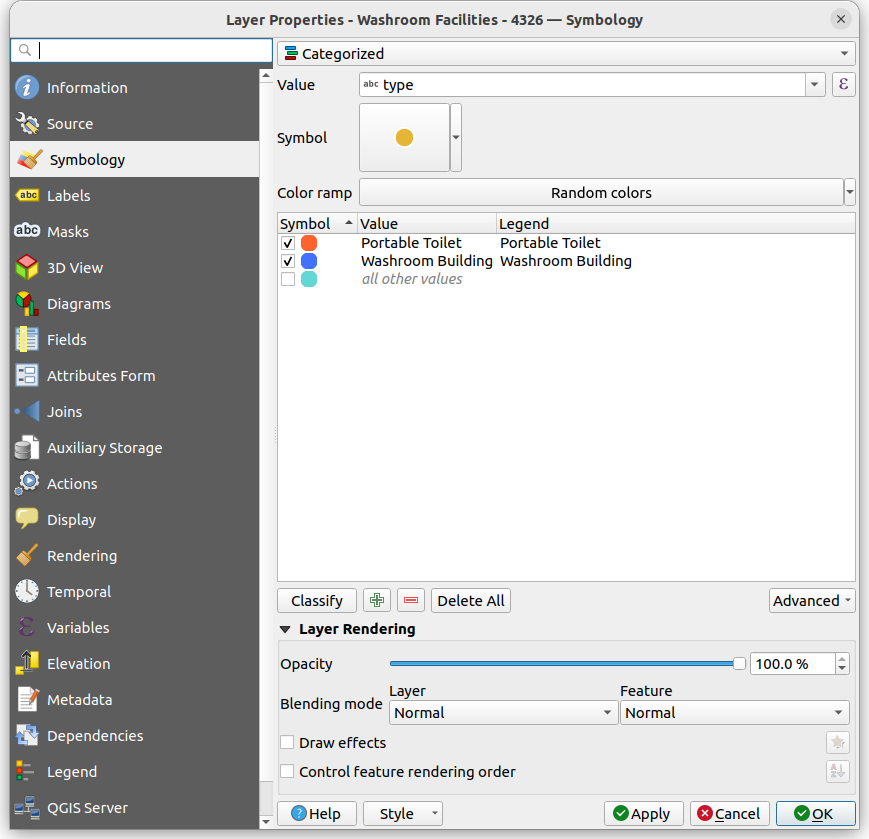
You can change the default colours and symbols of each category by double clicking on it.
Once you hit OK at the bottom-right, your map should update!
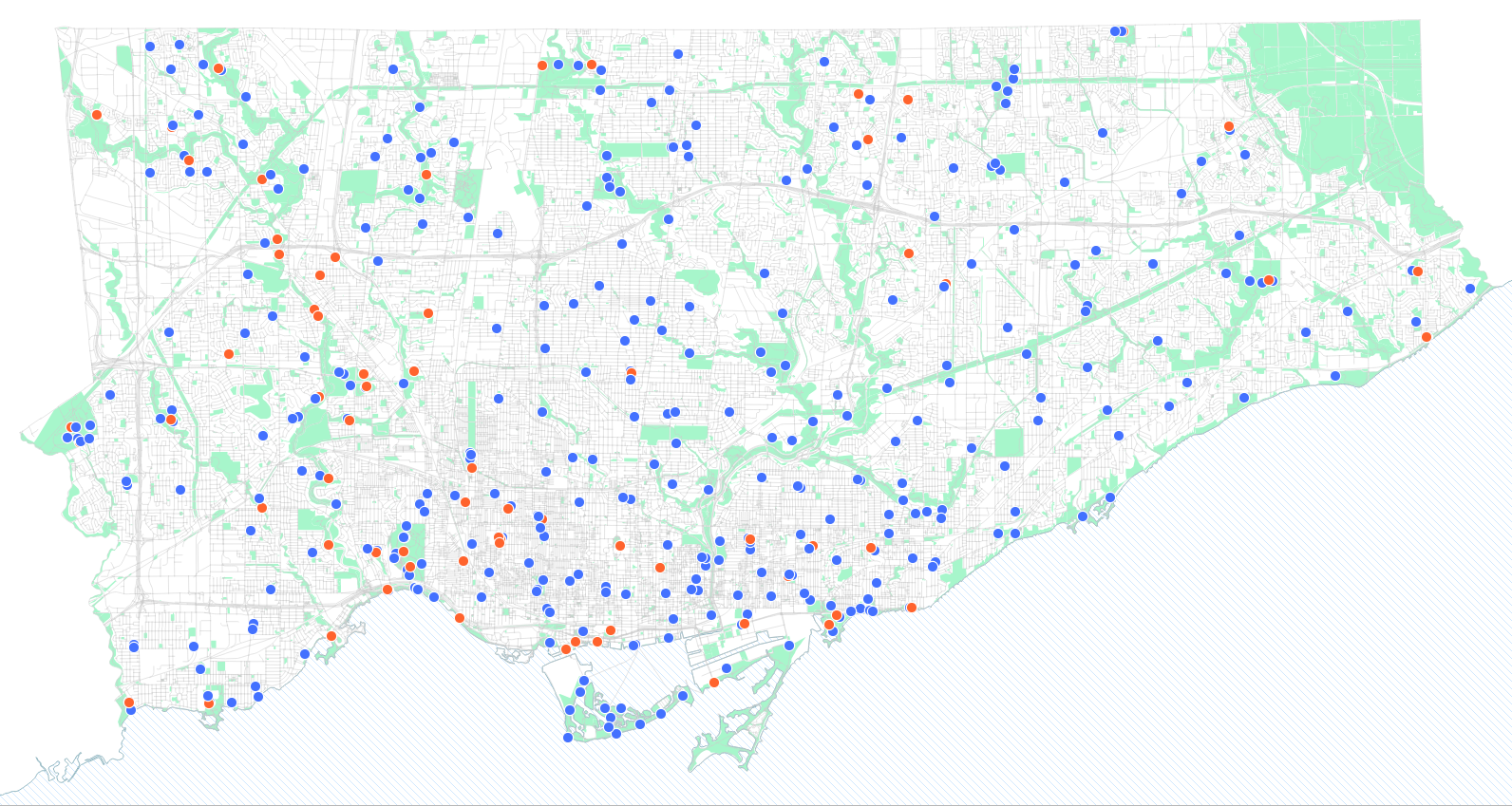
This was just the beginning! You can play with categorical styling for other layers as well. Here’s a couple ideas to improve the the reference layers
Style to colour green spaces based on their AREA_CLASS, to give different green spaces types different shades of green
Style the centreline data by FEATURE_CODE_DESC, to show major roads as thicker lines
Tip! with categorical styling you can also very quickly filter a dataset. Notice that once a layer is categorized, there are check marks next to each symbol, which allows you to easily hide or show different categories.
For example, if you only wanted to show parks and cemeteries in the green space layer, you can simply uncheck all the other layers.
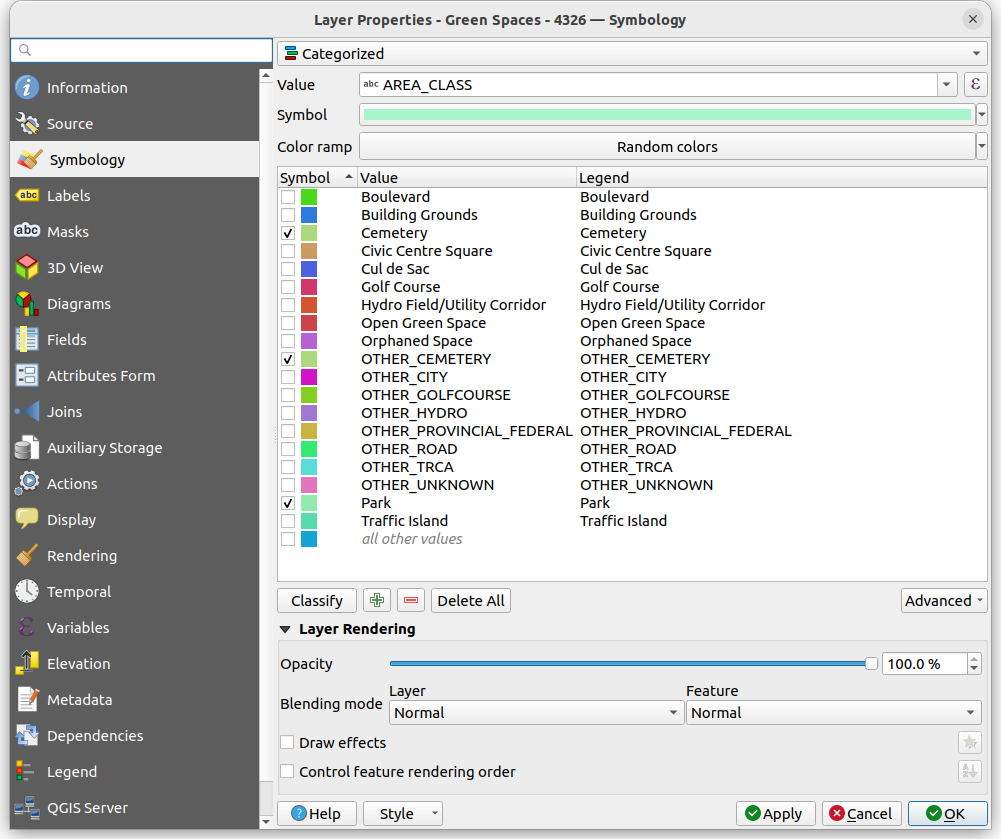
(Also note how the map has been rotated ~17-18 degrees, to horizontally align some of the features and reduce empty white space).
Styling numeric data
We often have ordinal or numeric data that we want to use to define our styling. For example, showing larger numbers in a column with a darker colour and smaller numbers with a lighter colour.
Let’s do a quick example, with data indicating camera locations for automated enforcement of speeding in Toronto. This dataset includes an integer column which denotes the number of speeding tickets for each automated camera in February 2025.
Automated enforcement camera locations dataset
We can colour these using the Graduated option in QGIS. This option allows us to pick a numeric column, and then classify or group the data into different “bins” or “breaks”, each with a colour, in this case ordered sequentially (more tickets, a darker red).
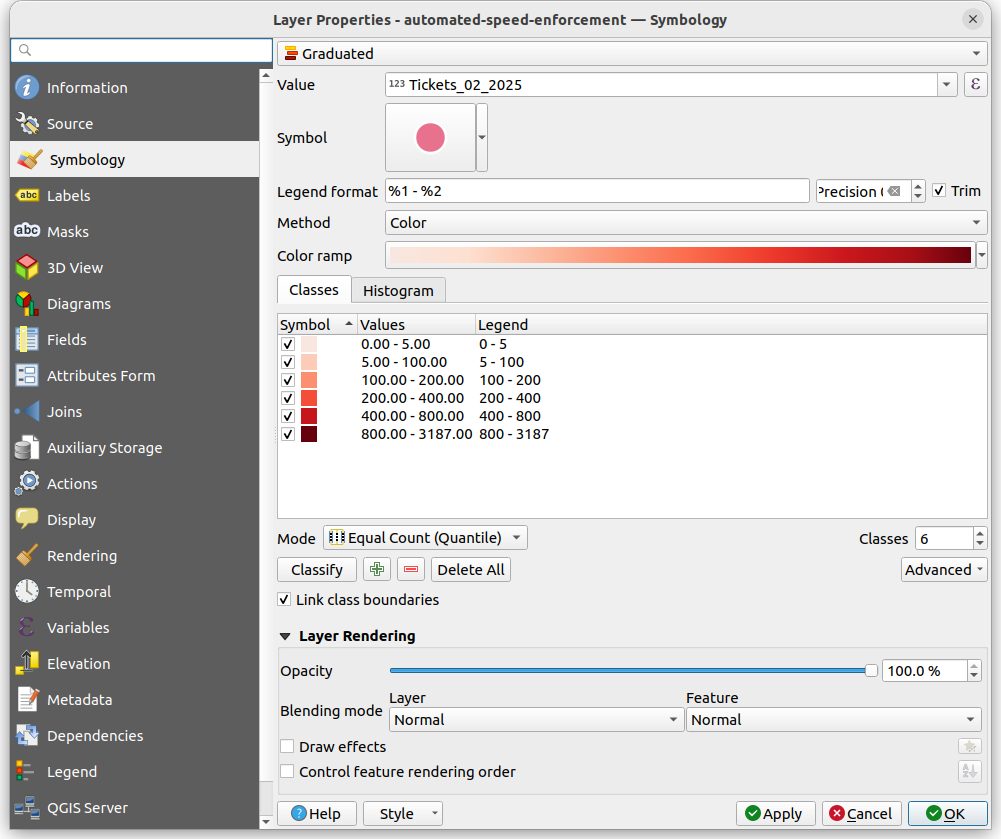
There are lots of options here for different sets of colours and ways to classify your data. The screenshots show what I did. Try playing with some of these different options
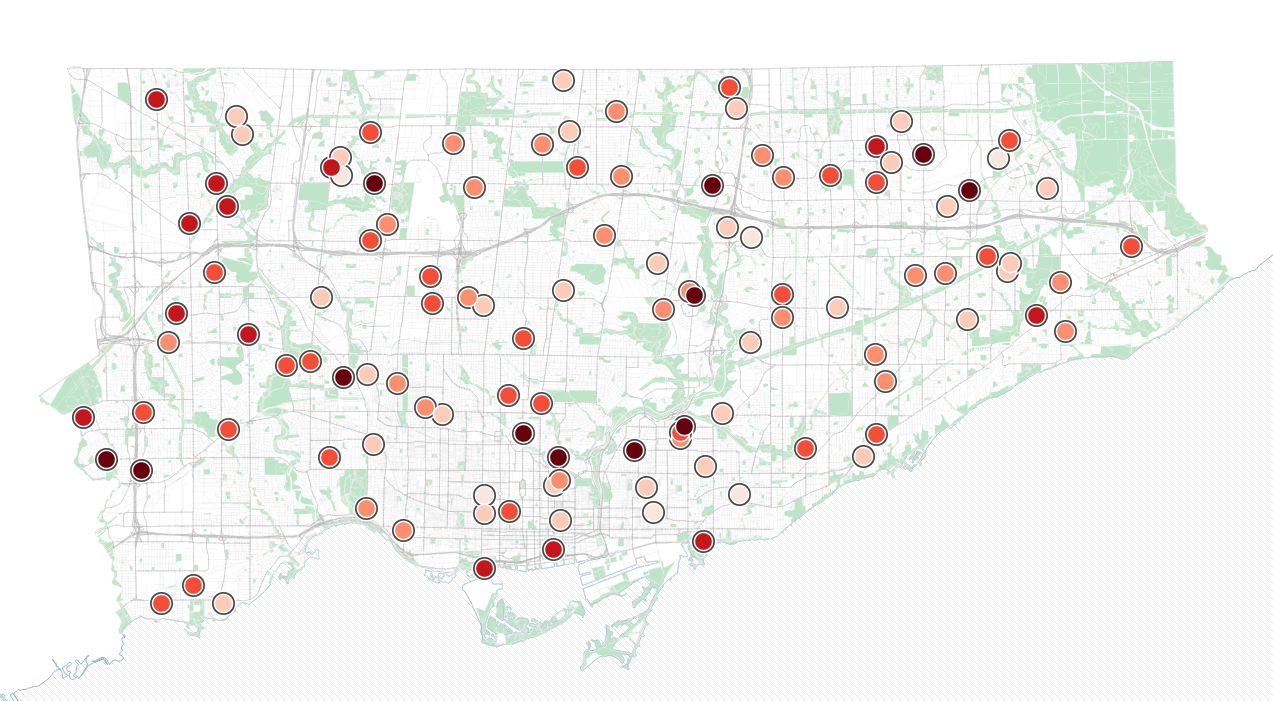
For more ideas and ways on how to classify and map numeric data via data-driven styles, check out our notebook on choropleth maps (maps where areas are shaded based on data values).
Layers and hierarchy
Maps are often the product of multiple layers, each with their own defined styling. Thinking about the ordering of the layers and their styling relative to each other goes a long way in making an effective map.
Well designed maps, especially thematic maps, often have a visual hierarchy of background and foreground - where the background provides geographic reference (e.g. streets, bodies of water), while the foreground are the key data that we want to show.
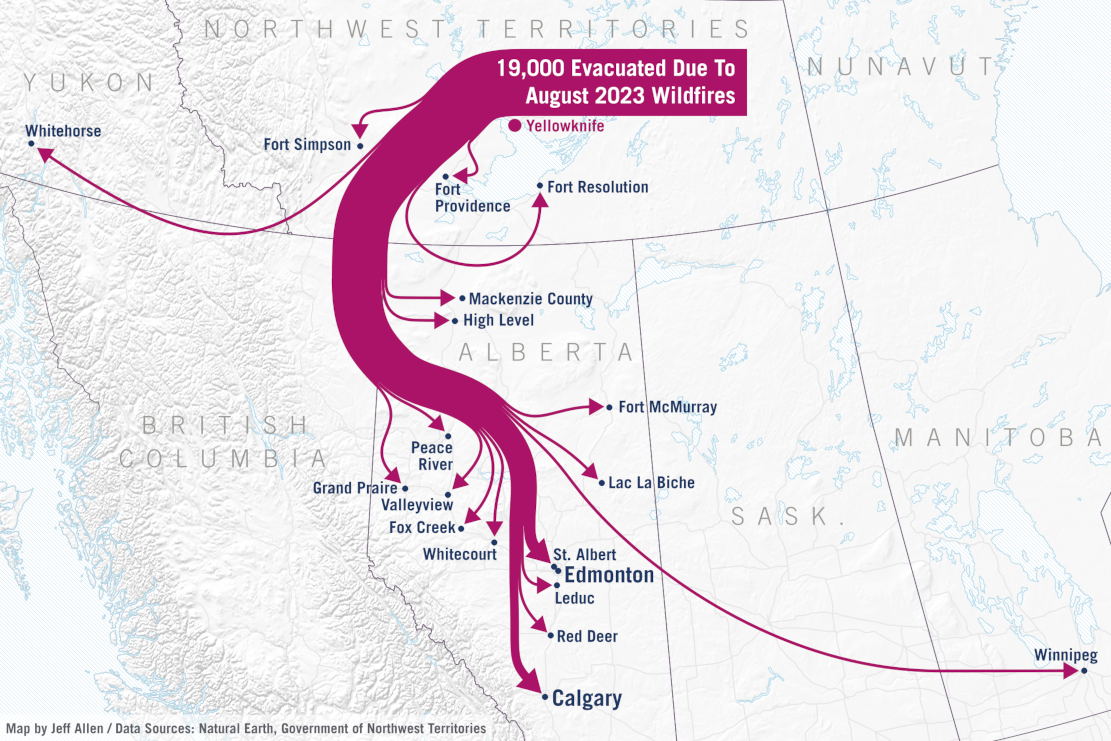
These are two examples of maps relating to the 2023 wildfires in Yellowknife that include a strong visual hierarchy of the key data (e.g. fire area, evacuation routes) relative to their geographic reference backgrounds. Both maps are quite simple from a data analytics standpoint, but were part of a story highlighting the scale and impact of the fires.
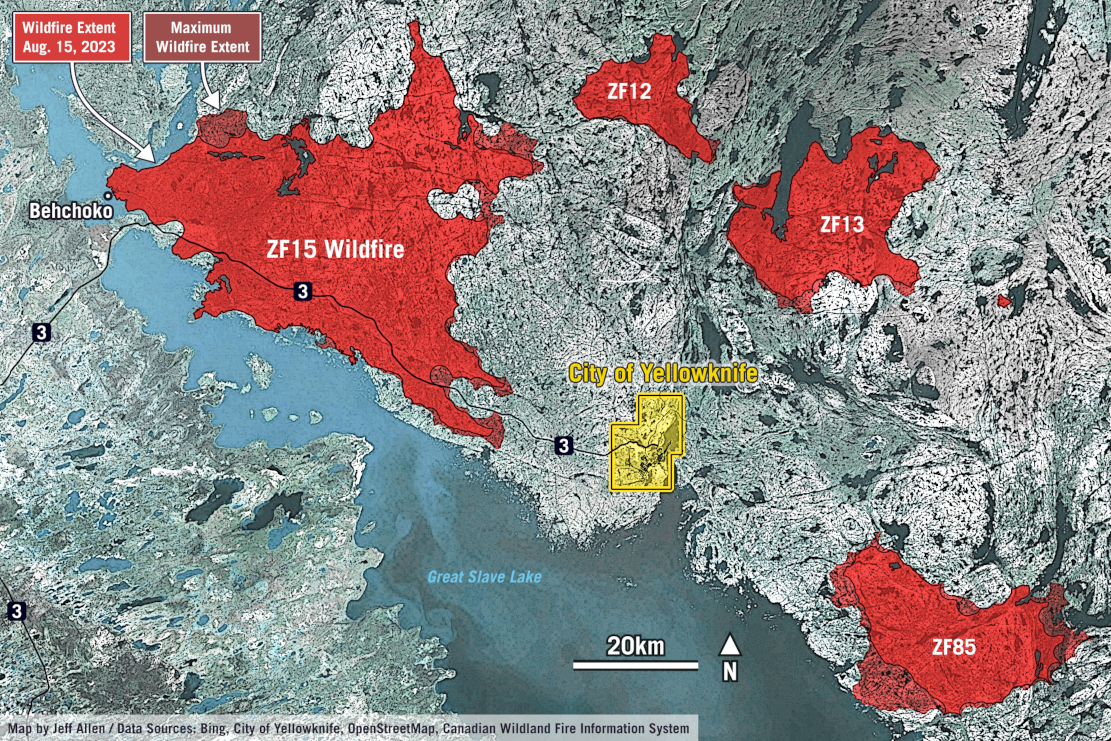
Map layouts
You’ll notice that many of the example maps above include graphic elements beyond specific data layers. Things like …
- Titles
- Explanatory text and annotations
- Place labels
- Borders
- Scale bar
- North arrows
- Legends
Not all maps and spatial data visualizations require all of the above, but they can often help communicate what is being shown on the map to your readers and audience.
The space that you would combine these items on top of map data layers are sometimes called map layouts, with each item sometimes called map elements or layout elements
Most mapping and data analysis software and related libraries (e.g. in QGIS, Python, R, etc.), provide tools for adding elements and creating map layouts. In QGIS you can go to Project then New Print Layout. This gives you a blank canvas for you to add your map data and layout elements. Here is a good step-by-step tutorial for layouts and exporting in QGIS.
In the layout view in QGIS, you can then export and save your map as .pdf, .png, or .svg.
While the options in QGIS and similar tools are fairly good, they are limited in terms of customization. If we are making maps for publication and communication material (i.e. for not just our internal research), we typically export our map data layers at a high resolution, and then design the layouts and related elements in a graphic design software (e.g. Inkscape, Illustrator, Canva, etc.). This allows for more customization in the design of layout elements, to help make a more professional final product.